Benchmarking ChatGPT-5 for Threat Intelligence Extraction

By B. Nathan Thomason (UALR CORE Center), in collaboration with Bastazo and Spencer Massengale.
Supported by U.S. Department of Energy award CR-0000031. Published August 26, 2025.
Critical-infrastructure defenders don’t just need more threat intelligence, they need machine-readable intel their systems can act on. Bastazo and the University of Arkansas at Little Rock’s CORE Center partner to do exactly that. Student analysts, practitioners, and AI work together to transform open-source threat reporting into structured records that operators can use to see context, prioritize risk, and choose effective remediations.
At the heart of this pipeline is an LLM extraction step that maps natural-language snippets to explicit fields to profile threat actors using SKRAM-related features (Skills Knowledge Resources Authorities Motivation). Since launch, OpenAI’s o4-mini has been our most reliable model for this translation.
On August 7, 2025, OpenAI released the ChatGPT-5 family (5, 5-mini, 5-nano). Same day tests suggested no obvious, runaway winner over o4-mini. To move beyond initial impressions, we ran a focused benchmark on August 11-13, 2025, comparing the 5-series models to o4-mini to evaluate extraction accuracy and consistency, latency, and cost-per-correct field.
This report shares our setup and early takeaways so that teams building threat-intelligence workflows can decide if and where ChatGPT-5 belongs in production.
Early Takeaways
- Our results suggest that ChatGPT-o4’s architecture has a faster response timing speed and improves reliability under both high and low-context scenarios.
- ChatGPT-5-mini briefly outperformed in high-context techniques, but failed on Mitigations and Detections, leaving GPT-o4-mini the most consistent and overall strongest performer for cybersecurity threat feature extraction tasks.
Methodology
To compare OpenAI models on equal footing, we embedded each one directly into the threat-analysis workflow and ran both a high-context source and a low-context source. High-context includes the then most recent CISA Cybersecurity Advisory - #StopRansomware: Interlock. We treated it as high-context because it explicitly describes many of the SKRAM attributes used in our threat reports. In contrast, for a representative low-context article, we used Dark Reading’s “Nimble ‘Gunra’ Ransomware Evolves With Linux Variant”. We treated it as low-context because it offers fewer explicitly stated profiling details, especially around TTPs.
The workflow is shown in Figure 1. We first create a threat-report object from each article URL and then use a web scraper to fetch and normalize the HTML. We send the extracted text to an OpenAI agent along with a structured prompt set to align the output to the given schema. We use a distinct prompt for each phase of the threat extraction to break up the complex tasks. Our analysis has found the LLM performs better on smaller, defined tasks than single-shot feature extraction. Likewise, separate prompts exist for feature extraction, adversarial technique extraction, mitigation technique extraction, and remediation playbook generation.
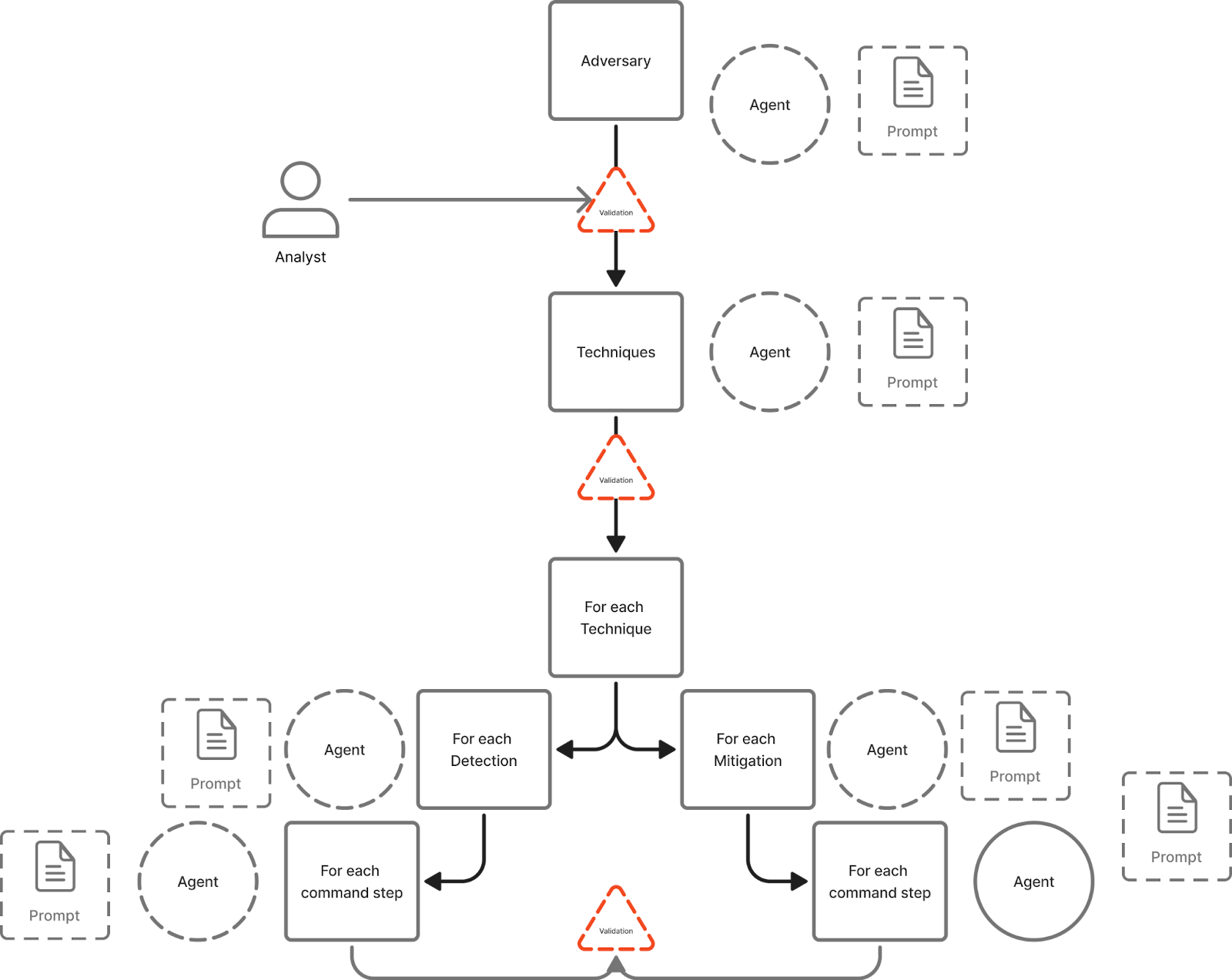
In each phase, the model extracts specified fields only when the article states them explicitly or when a clearly supported inference can be made. Otherwise, it should leave the field blank.
The model scoring criteria includes the following:
- Latency: time to first valid, schema-conformant response.
- Coverage: number of correctly populated report fields vs. the ground-truth fields present in the source.
- Inference accuracy: correctness of any model-made inferences used to fill fields not stated verbatim.
- Retry count: how many analysis attempts were required to achieve an overall satisfactory report.
This setup lets us measure not just what each model can extract, but how quickly, how reliably, and how often it needs a second pass.
Results
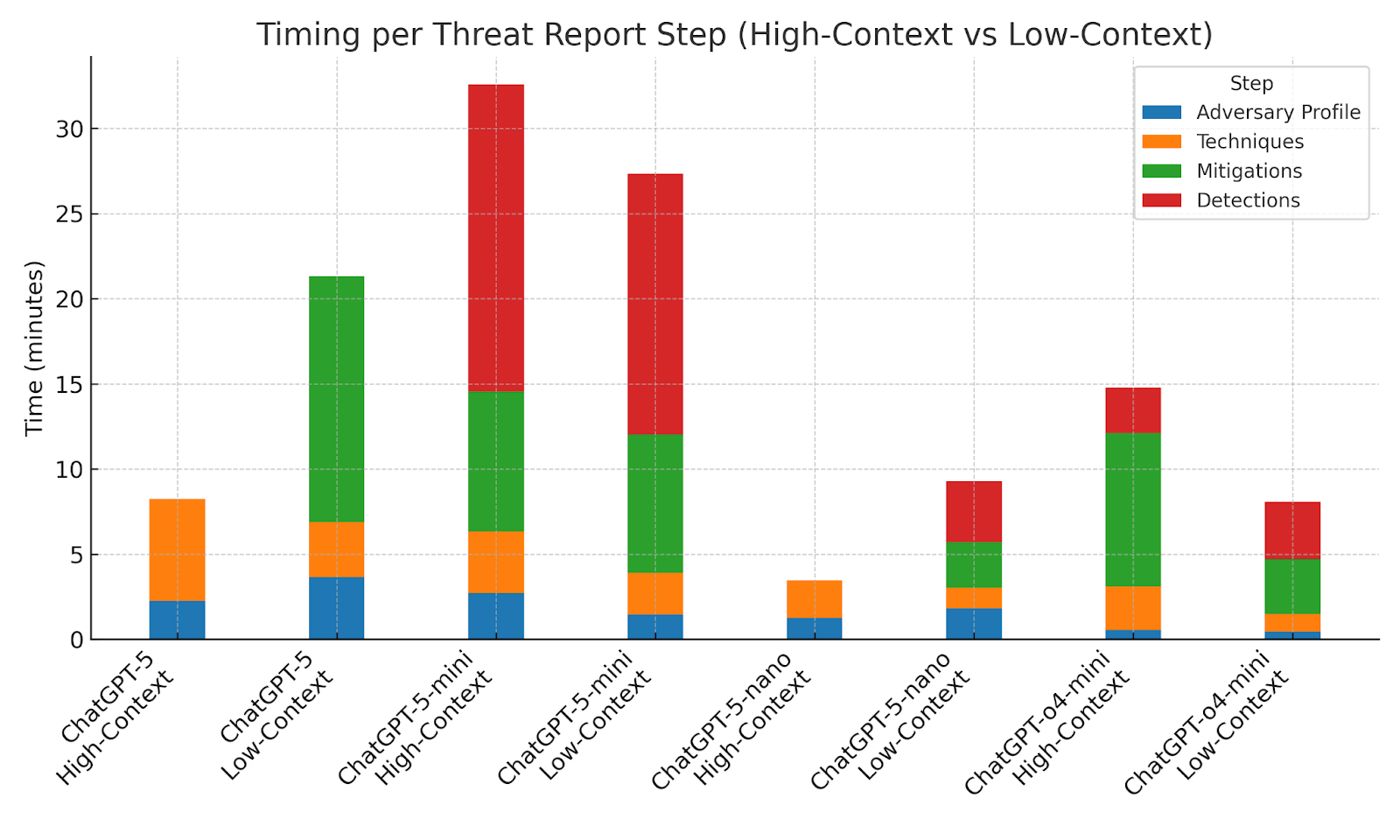
As a whole, ChatGPT-o4-mini outperformed each of the ChatGPT-5 models in regards to the amount of processing time required to return a response, with ChatGPT-5 and ChatGPT-5-nano being unable to return some Mitigations and Detections responses entirely. Even in low-context scenarios, ChatGPT-o4-mini consistently completed its analysis in a number of minutes, whereas the ChatGPT-5 models exhibited consistent latencies up to 30 minutes. These results suggest that ChatGPT-o4’s architecture not only benefits response timing speed but also improves reliability under both high and low-context scenarios.
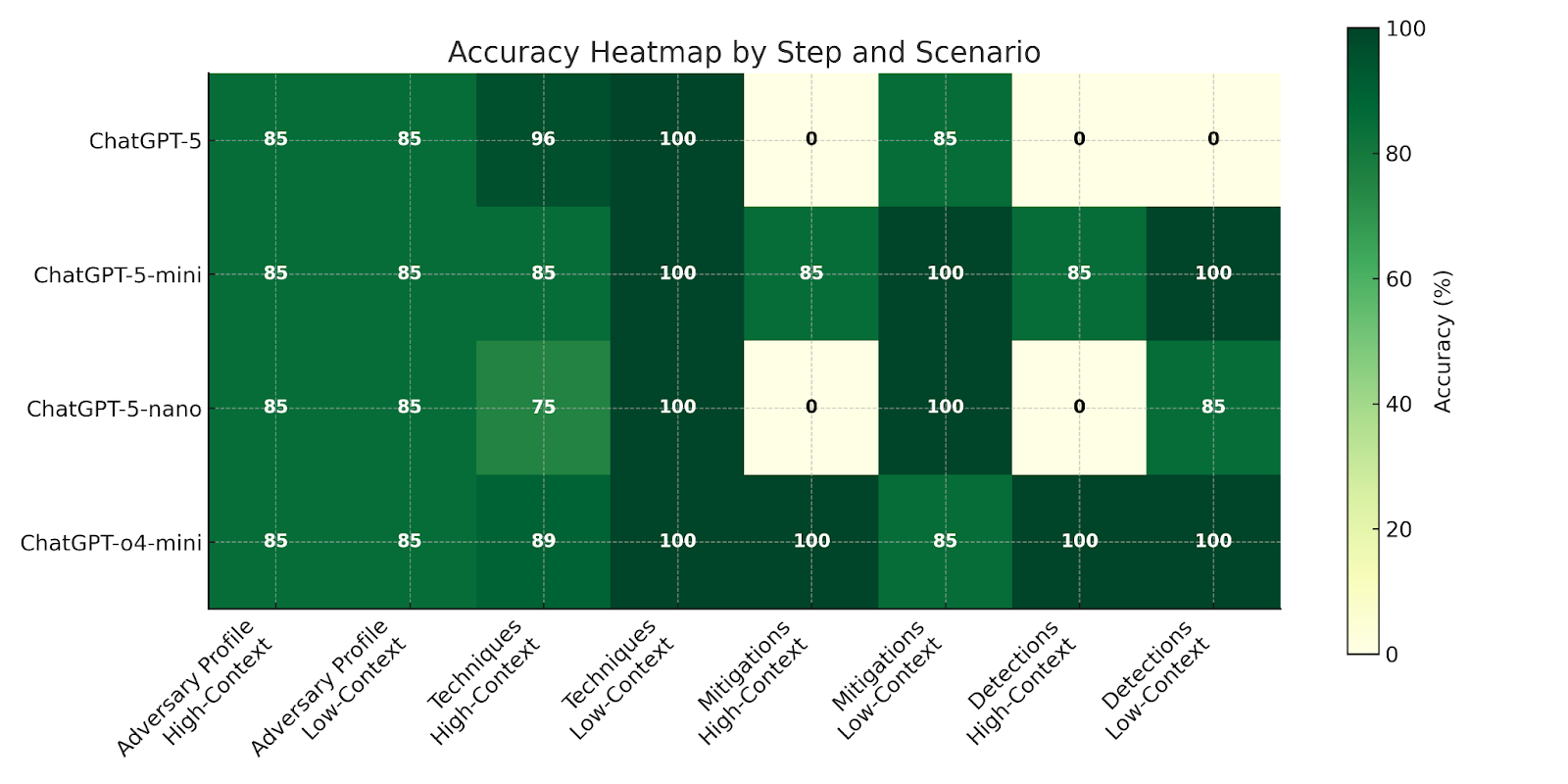
In terms of accuracy, performance quality between the different models was slightly more nuanced than the timing results would lead one to assume. Although ChatGPT-o4-mini maintained the most consistent accuracy scores throughout both high and low-context scenarios, ChatGPT-5 did outperform the model in the Techniques step under high-context conditions. This advantage would have been more promising if the model had not failed to return responses for the Mitigations and Detections steps, despite subsequent analysis attempts. ChatGPT-5-mini demonstrated strong overall consistency in its accuracy, but was overshadowed by ChatGPT-o4-mini’s performance. And ChatGPT-5-nano, similar to ChatGPT-5, also failed to provide Mitigations and Detections responses during the high-context scenario. These results suggest that smaller models such as ChatGPT-o4-mini and 5-mini provide more reliable performance overall, but the larger ChatGPT-5 models are capable of performing analysis to a higher degree of success when provided with sufficient context.
It’s worth noting that accuracy is not the same as usefulness for technique extraction. Low-context outputs often appear more accurate because the model lists only a few generic techniques (for example, mapping ransomware to T1486: Data Encrypted for Impact). That may be correct but offers little operational value. Higher-context outputs provide richer, actionable detail for operations, even if their technique labels score lower on strict accuracy.
Discussion
The results of these tests indicate that, for the sample reports in the limited timeframe, the ChatGPT-5 models underperformed in comparison to their ChatGPT-o4-mini counterpart. On average, all ChatGPT-5 models required significantly longer processing time than o4-mini to return successful responses, and in several cases the ChatGPT-5 models were unable to successfully provide responses for the Mitigations and Detections steps of threat reports. The ChatGPT-5 models did notably return much more contextually detailed rationale justifying their feature responses, but this improvement did not translate to higher feature accuracy and therefore limits their practical benefit in threat report creation, where actionable feature responses outweigh the value of the narrative depth provided by the rationale response.
However, ChatGPT-5 model performance variability may have been influenced by external factors affecting the OpenAI API during the evaluation period, such as fluctuations in API availability or demand. During multiple tests of the ChatGPT-5 models, various threat report steps experienced unexplained timeouts or substantial query latency spikes, often within 10-15 minute intervals scattered unpredictably across the threat report creation process. These irregularities were not observed during the evaluation of the ChatGPT-o4-mini model, and coincided with the immediate post-launch period of the ChatGPT-5 models when heightened user activity could have placed a strain on OpenAI API infrastructure.
Conclusion
Our initial evaluation findings of the OpenAI ChatGPT-5 models suggest that despite architectural advancements, the ChatGPT-5 models might not currently offer an advantage over o4-mini for time-sensitive, accuracy-critical workloads in which the model must either analyze incredibly large amounts of contextual material or make large amounts of inferences. The greater depth and clarity of the ChatGPT-5 models’ rationale output is outweighed by the longer completion times and higher failure rates in later threat report steps, and only marginal accuracy improvements in specific contexts. It is plausible that these poor performance outcomes were caused by post-launch availability degradation of the OpenAI API, and so future work ought to be conducted which re-runs these tests during a known period of stable model availability to determine whether the observed timing and reliability issues persist. Additional investigation into ChatGPT-5 model prompt optimization could assist in the determination of whether its supposed improvements in detailed reasoning capabilities can be leveraged without compromising throughput or threat report step completion rates.
Works Cited
Cybersecurity & Infrastructure Security Agency. “#StopRansomware: Interlock.” CISA, 2025. https://www.cisa.gov/news-events/cybersecurity-advisories/aa25-203a. Accessed 14 Aug., 2025.
Montalbano, Elizabeth. “Nimble 'Gunra' Ransomware Evolves With Linux Variant.” DarkReading, 2025. https://www.darkreading.com/threat-intelligence/nimble-gunra-ransomware-Linux-variant. Accessed 14 Aug., 2025.
Appendix
ChatGPT-5: High-Context Scenario
As can be seen from the Celery debug log in Pycharm, ChatGPT-5’s analysis of the Adversary Profile threat report step took approximately 2 minutes and 15 seconds to complete.

During the model’s analysis, it incorrectly identified the adversary’s exploit capability as “Low,” providing rationale which justified this identification due to the fact that the provided source content cited no CVE or custom exploit use. However, per the instructions given to the model in the adversary profiling step prompt, an adversary’s exploit capability should not only be determined by how successfully they are able to use CVEs or develop custom exploits, but also by the degree to which the adversary is capable of successfully leveraging existing exploit procedures.
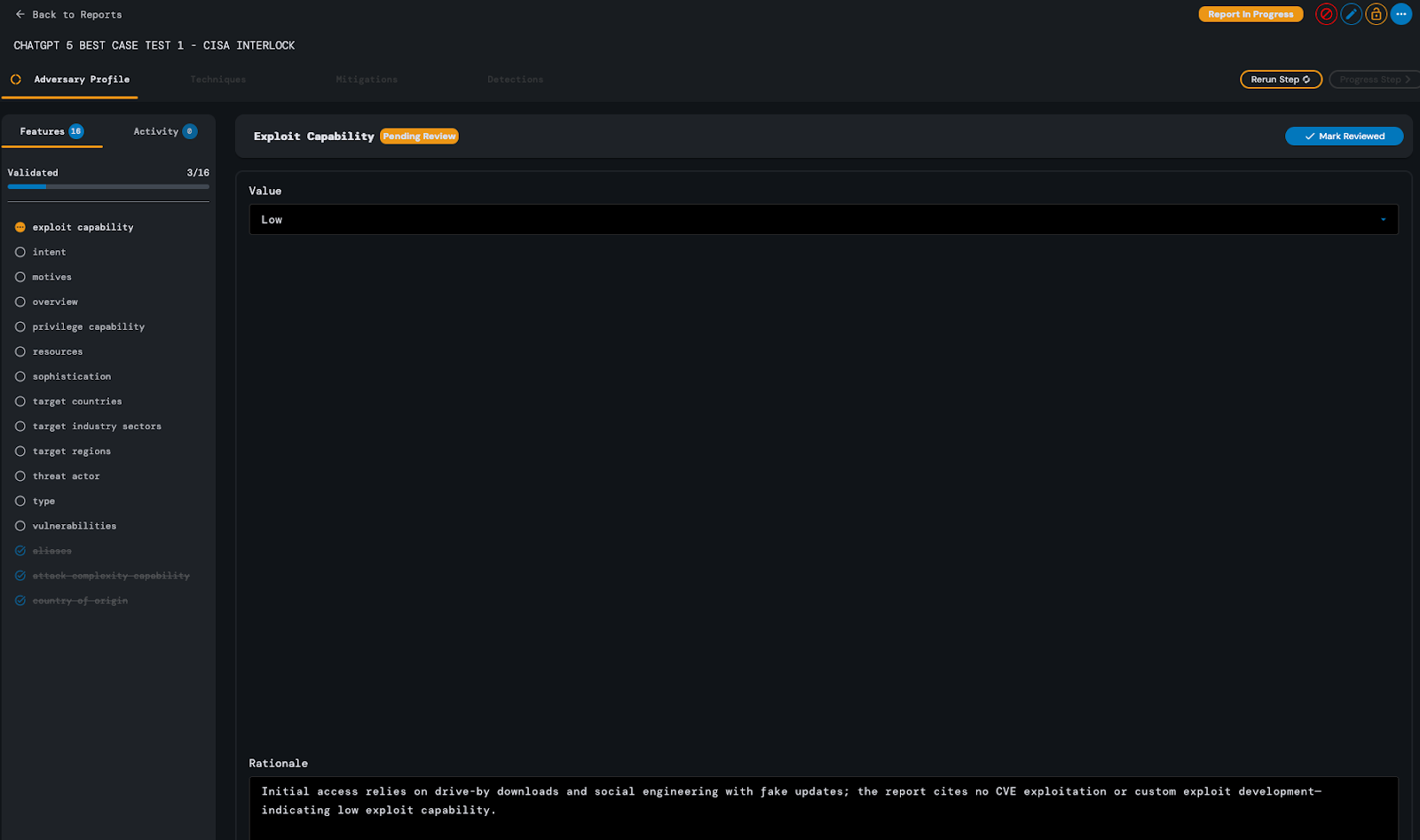
Asides from this one error, the model returned a satisfactory response for the Adversary Profile step and no reruns of the analysis were required.
ChatGPT-5 took just under 6 minutes to completely analyze the MITRE ATT&CK techniques contained in the source content.

Out of all 28 MITRE techniques explicitly stated in the source content, ChatGPT-5 successfully identified 27 of them. It chose to identify one technique using both its inferred base ID and the correct explicitly mentioned sub-technique, and for a different technique the model neglected to identify its explicitly stated base ID, instead only using its explicitly stated sub-technique ID. Aside from these errors, the model provided a satisfactory response for the Techniques analysis step.
After approximately 25 minutes of allowing the model to perform analysis on the Mitigations and Detections steps of the threat report, the process was terminated as that was an unreasonable amount of latency for threat report processing time in practice. This model was never able to successfully complete the Detections step of this threat report even across multiple subsequent reruns the days following the creation of this report.
ChatGPT-5: Worst-Case Scenario
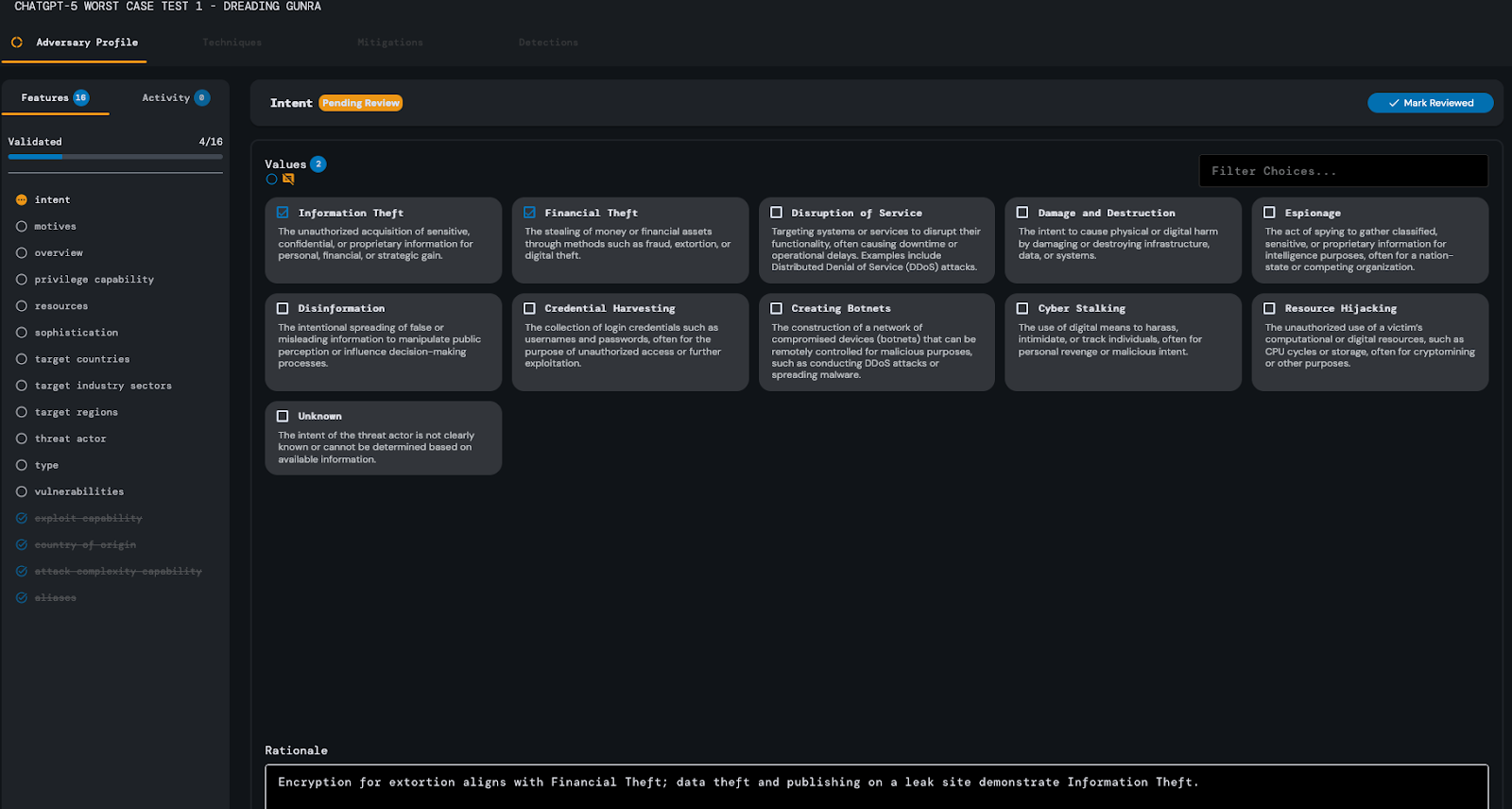
When analyzing the “worst-case” source content, ChatGPT-5 took approximately 3 minutes and 39 seconds to complete the Adversary Profile step of the threat report.

During its analysis, it incorrectly identified the adversary’s exploit capability as “Low,” justifying this decision due to the lack of CVEs or exploits mentioned in the source content.

Similarly to the best-case scenario, however, this response was considered inaccurate because the exploit capability feature is not limited to successfully executed CVEs. Additionally, the model failed to identify disruption of service as an intent of the adversary, which is a staple in ransomware attacks.
ChatGPT-5 took approximately 3 minutes and 15 seconds to complete the analysis of the Techniques step of the threat report. After making all of its inferences, it returned a response

containing 4 MITRE ATT&CK techniques - T1027, T1083, T1486, and T1567. These results were satisfactory, but the analysis was reran additional times to determine whether the quality of the response would improve upon subsequent analysis. While these analyses contained applicable MITRE ATT&CK techniques not included in the original model response, they also included less applicable techniques as well, and so their quality did not substantially improve over the original.
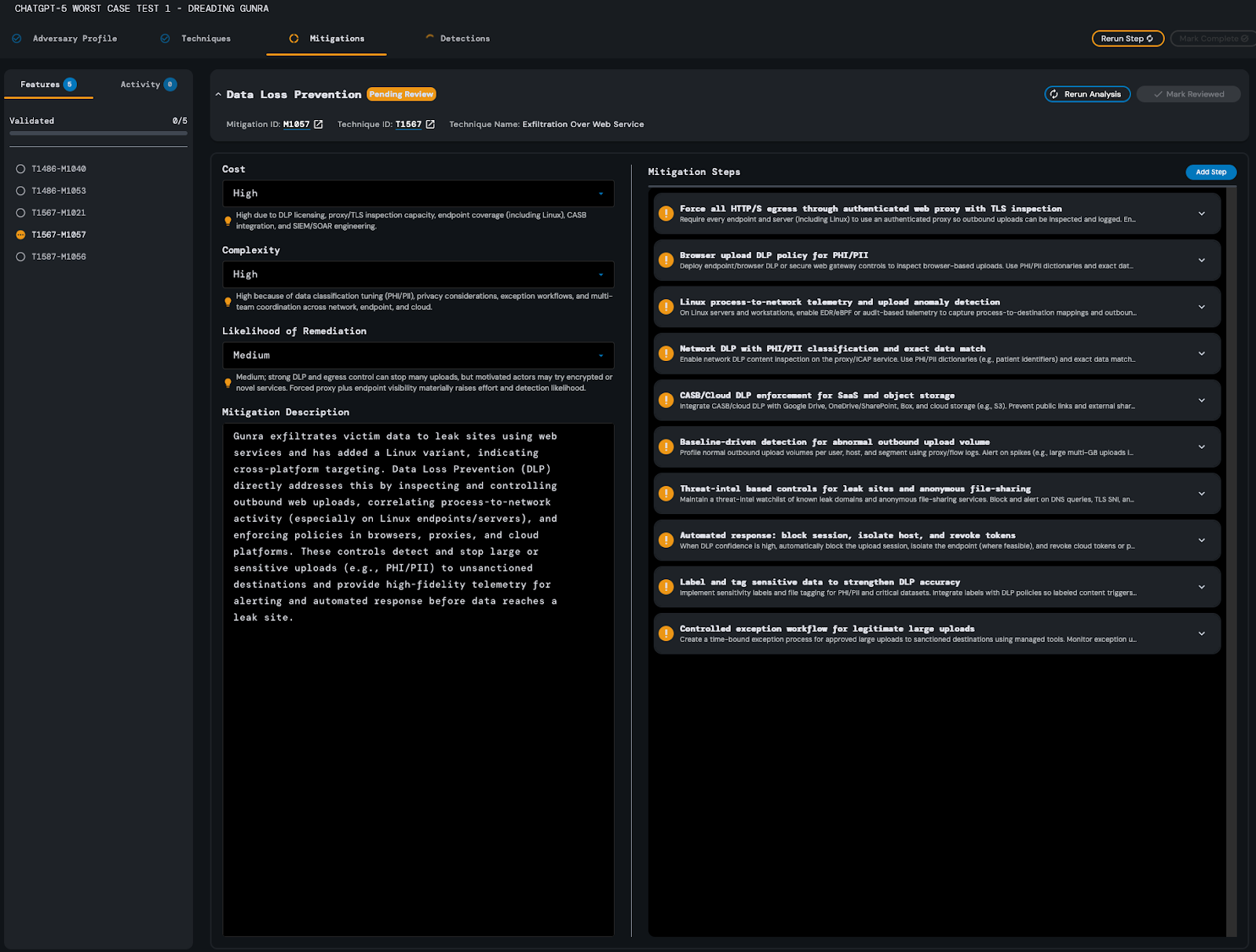
After about 14 minutes and 25 seconds, ChatGPT-5 completed the analysis of the Mitigations step of the threat report. Each mitigation contained an average of 7 steps, with each step containing an average of 3 commands. In order to save time, the precise attributes contained in each command were not validated - however, the mitigation steps and their commands as a whole were validated and judged as satisfactory on this first analysis. Additionally, it was noted that the model’s rationale for each feature provided remarkable contextual information regarding how each mitigation feature related to the source content from which it was inferred.
ChatGPT-5 was unable to complete the Detections step of the source content analysis in less than 25 minutes, even across multiple different reruns initiated on the following days, and so its analysis was terminated.
ChatGPT-5-mini: Best-Case Scenario
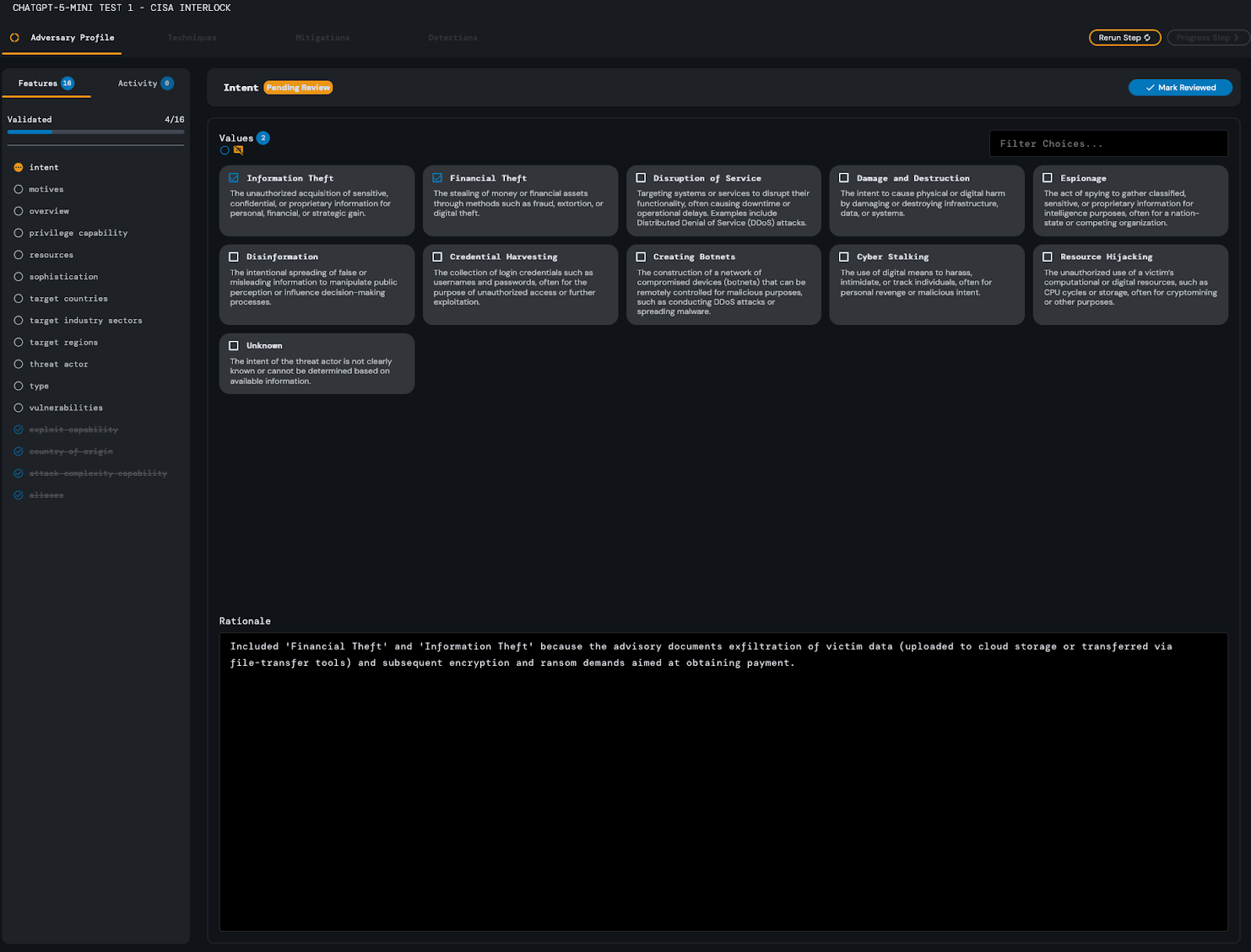
ChatGPT-5-mini required about 2 minutes and 44 seconds of processing time in order to complete the Adversary Profile analysis step of the CISA Interlock advisory threat report.

During its analysis, the model neglected to select disruption of service as an intent attribute - however, the rest of its response was satisfactory.
The Techniques portion of ChatGPT-5-mini’s analysis took approximately 3 minutes and 36 seconds of processing time. Out of all 28 MITRE ATT&CK techniques listed in the provided

source content, ChatGPT-5-mini successfully identified 24 of them. Notably, the model correctly inferred an applicable MITRE ATT&CK ID not included in the original source content, T1090.
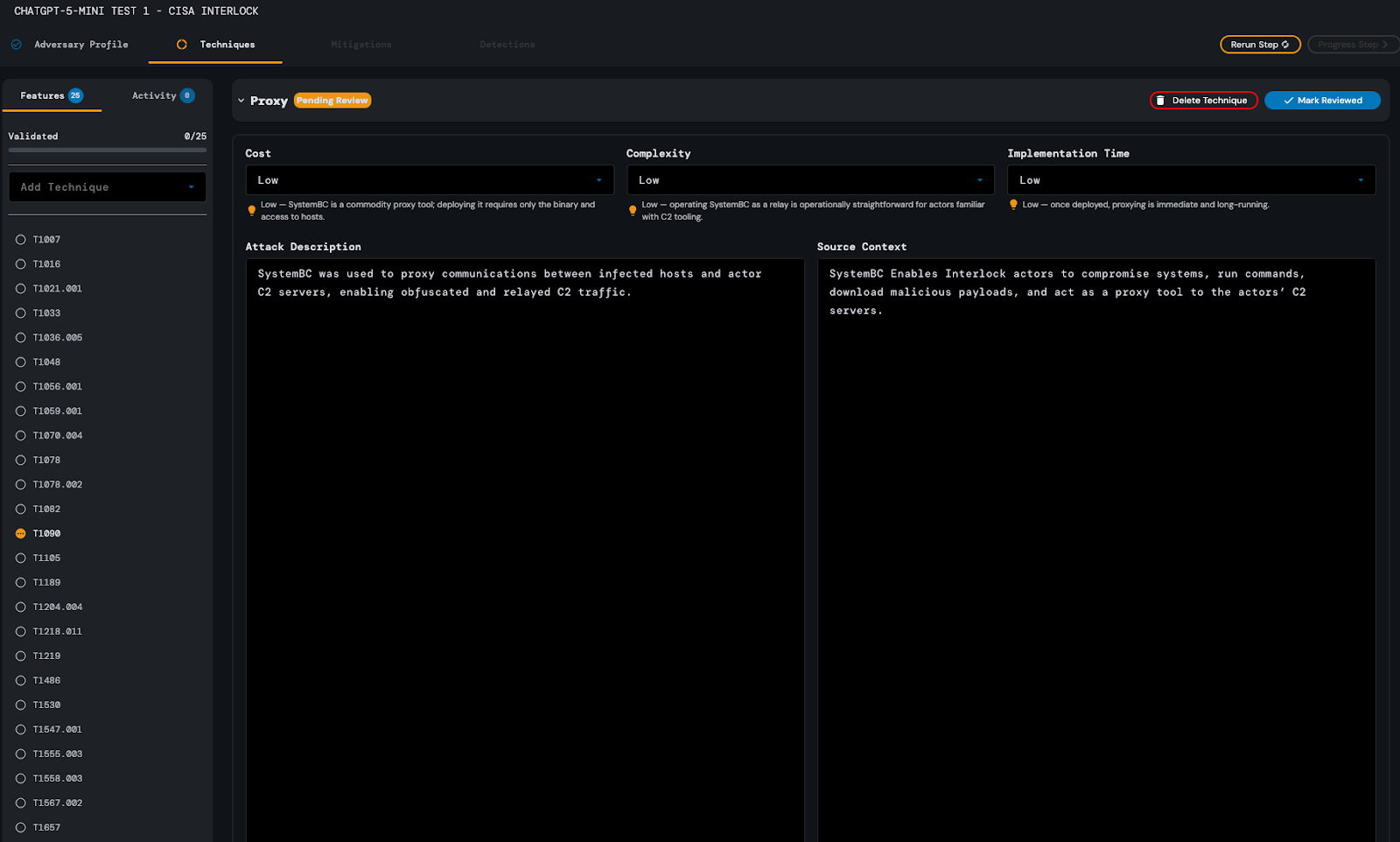
This response was evaluated to be satisfactory with minimal to no editing required on the part of the analyst.
On two subsequent reruns, ChatGPT-5-mini was unable to successfully analyze the source content during the Mitigations and Detections steps of the threat report after approximately 25 minutes, and so its analysis was terminated. On a third rerun performed the following day, ChatGPT-5-mini successfully analyzed the Mitigations and Detections steps of the threat report and returned a response containing 43 mitigations and 88 detections. It took approximately 18

minutes to complete the Detections step analysis, and 8 minutes and 14 seconds to complete the Mitigations step analysis. Each detection contained an average of 3 steps, with each step containing an average of 2 commands, and each mitigation contained an average of 4 steps, with each step containing an average of 2 commands. Although the analyst was required to edit several commands contained in several of the mitigation steps, these responses as a whole were deemed satisfactory.
ChatGPT-5-mini: Worst-Case Scenario
After approximately 1 minutes and 28 seconds, ChatGPT-5-mini successfully completed its analysis of the Adversary Profile step of the Gunra Ransomware threat report. Similarly to the

other models, ChatGPT-5-mini incorrectly identified the adversary’s exploit capability as low, citing a lack of successful CVE exploits described in the source text. The model also failed to
identify financial theft as an intent of the adversary, but did successfully identify information theft and disruption of service. Asides from these two errors the rest of its response was evaluated to be satisfactory and no additional edits were required on the part of the analyst.
ChatGPT-5-mini successfully completed its analysis of the Techniques step of this threat report in approximately 2 minutes and 26 seconds. It identified three MITRE ATT&CK techn-

iques, T1083, T1486, and T1567. Its analysis of these techniques was evaluated as satisfactory, but additional reruns were initiated to determine whether the quality of the model’s response would improve over time. Results from these subsequent reruns were not of significantly better quality than the original, and required similar amounts of processing time.
After approximately 8 minutes and 8 seconds, ChatGPT-5-mini successfully

completed its analysis of the Mitigations step of the threat report. Its response contained 4 mitigations, each with an average of 8 steps. Each step contained an average of 3 commands. No edits were required on the part of the analyst and this response was evaluated as satisfactory.
The Detections step of this threat report required approximately 15 minutes and 19 seconds.

ChatGPT-5-mini’s response contained 15 detections, each of which contained an average of 6 steps. Each step was composed of an average of 3 commands, all of which were evaluated as satisfactory. No additional edits were required on the part of the analyst.
ChatGPT-5-nano: Best-Case Scenario
ChatGPT-5-nano only required a remarkable 1 minute and 16 seconds of processing time in order to analyze the Adversary Profile step of the CISA Interlock advisory. During its analysis,

the model failed to identify disruption of service as an adversary intent, but the rest of its response was satisfactory and required no additional editing on the part of the analyst.
ChatGPT-5-nano required approximately 2 minutes and 12 seconds to complete the Techniques analysis step of the CISA Interlock advisory. Out of the 28 MITRE ATT&CK

techniques listed in the article, ChatGPT-5-nano successfully identified 21 of them. The quantity or quality of its response did not significantly improve upon subsequent reruns.
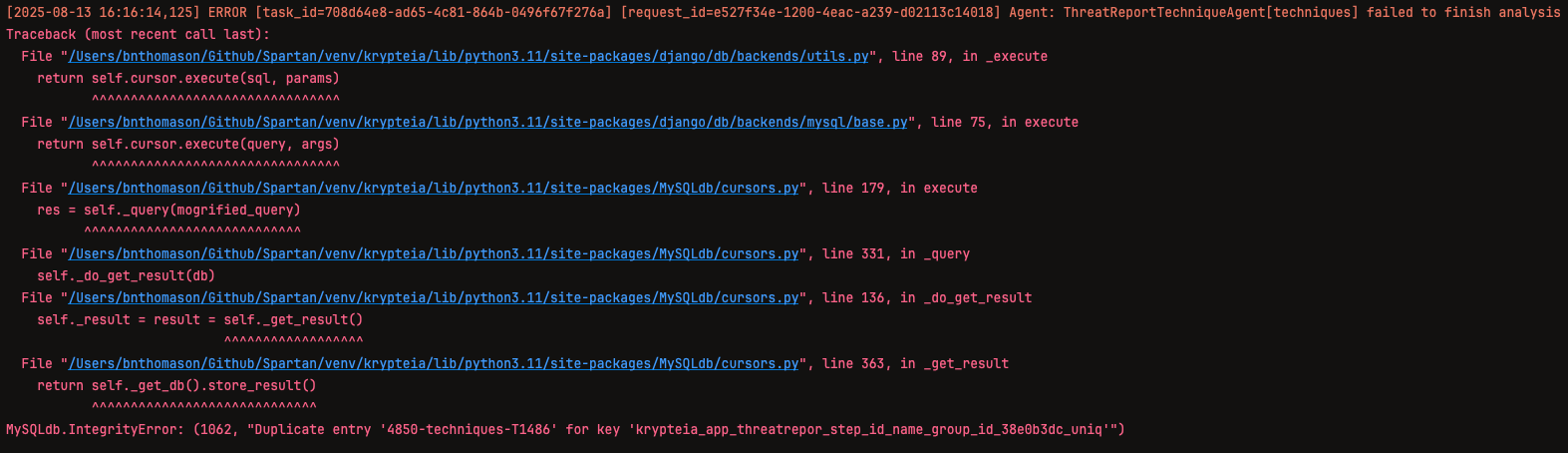
During the Mitigations and Detections steps of the threat report, ChatGPT-5-nano encountered multiple analysis failure and validation errors. Some mitigation or detection steps simply failed to complete, produced invalid command types, invalid JSON, or caused other similar errors.


Due to these errors and the large amount of time required to process the Mitigation and Detections steps, ChatGPT-5-nano’s analysis of this article was terminated.
ChatGPT-5-nano: Worst-Case Scenario
ChatGPT-5-nano required approximately 1 minute and 50 seconds in order to complete its analysis of the Adversary Profile step of the Gunra Ransomware threat report. Like the other

models used during these tests, it mistakenly attributed the adversary’s exploit capability as low, citing the lack of explicit mention of successful CVE exploits as its reasoning for this decision. It also failed to identify disruption of service as an intent of the adversary. Asides from these two errors, its response was evaluated as satisfactory and no other edits were required on the part of the analyst.
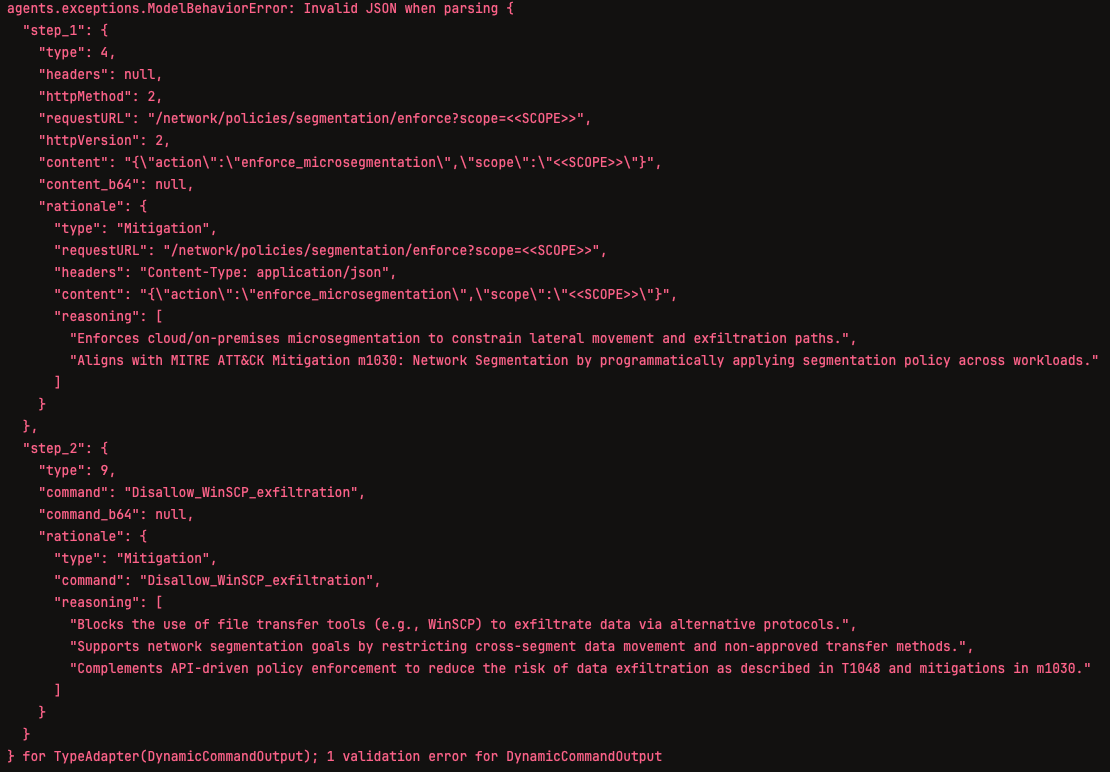
During its first attempt at analyzing the Techniques step of the threat report, the model returned an invalid response containing duplicate MITRE ATT&CK IDs. On the rerun attempt
immediately following the error, the model returned a response containing two MITRE ATT&CK IDs, T1486 and T567.001. It required approximately one minute and 12 seconds to complete this analysis, and while its response was satisfactory, additional rerun attempts were

initiated to determine whether the model’s response would improve over time. The quality of these subsequent responses were not significantly better or worse than the original, and required similar amounts of processing time to complete.
After approximately 2 minutes and 41 seconds, ChatGPT-5-mini successfully completed its

analysis of the Mitigations step of this threat report. Its response contained 4 mitigations, each with an average of 4 steps. Each step contained an average of 2 commands. This response was evaluated as satisfactory, and no further edits were required on the part of the analyst.
ChatGPT-5-mini’s analysis of the detections step of the Gunra Ransomware threat report required approximately 3 minutes and 35 seconds, after which the model returned a response

containing 11 detections. Each detection was composed of an average of 4 steps, and each step had an average of 2 commands associated with it. One mitigation required all of its steps to be corrected by the analyst, but the rest of the response was evaluated as satisfactory.
ChatGPT-o4-mini: Best-Case Scenario
In contrast with the other models, ChatGPT-o4-mini required approximately 33 seconds to complete the Adversary Profile analysis step of the CISA Interlock advisory.

During its analysis, similar to the other models, it mistakenly identified the adversary’s attack complexity as “Low.” ChatGPT-o4-mini also neglected to identify information theft or disruption of service as intents of the adversary discussed in the advisory.
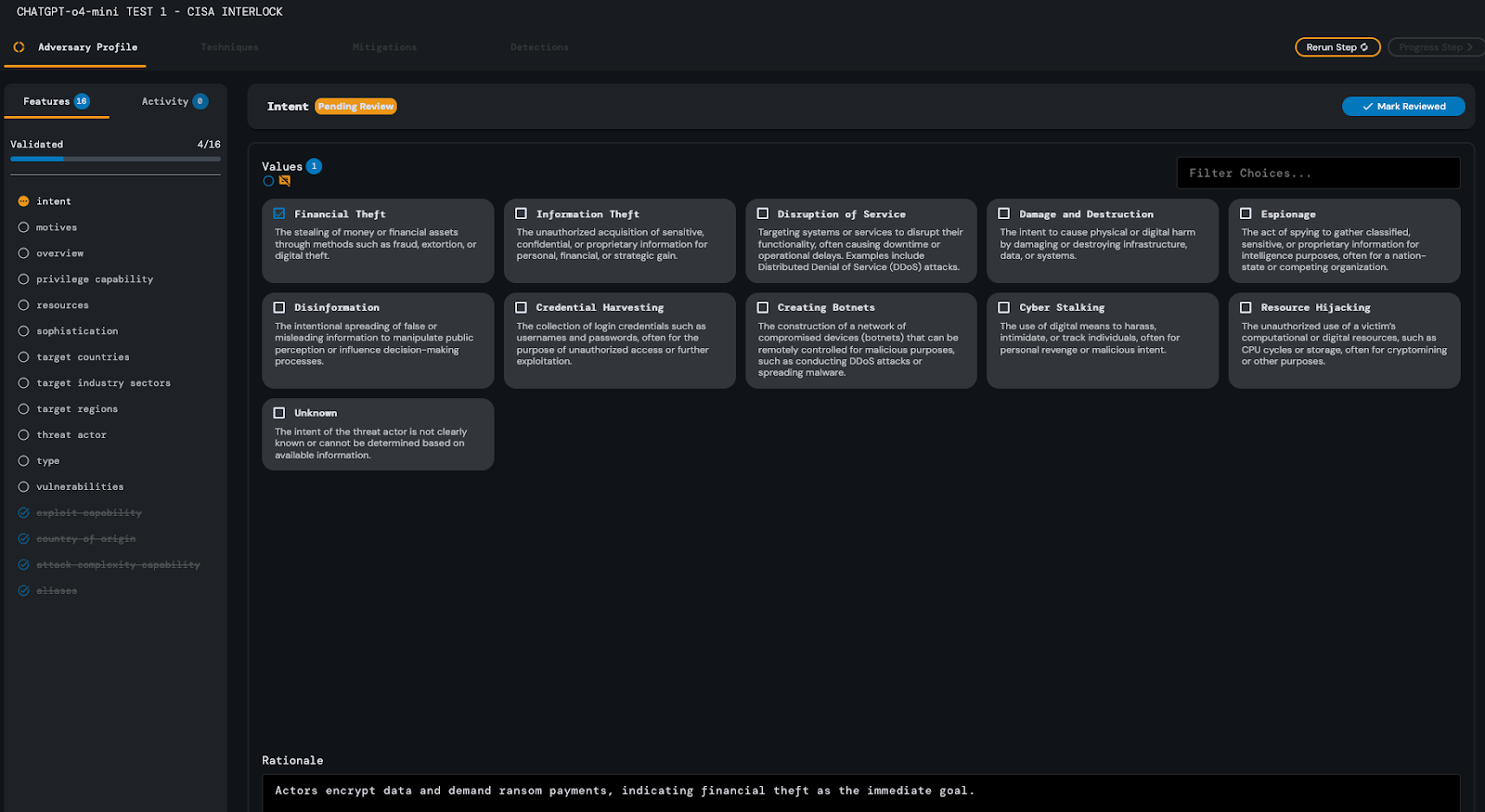
The rest of its response was evaluated and deemed satisfactory, requiring no further corrections on the part of the analyst.
ChatGPT-o4-mini completed the Techniques analysis step of the threat report in approximately 2 minutes and 34 seconds. Out of the 28 MITRE ATT&CK techniques listed in

the advisory, the model successfully identified 25 of them. The quality of its analysis of the features associated with each MITRE ATT&CK technique did not noticeably differ from the analyses of the other models.
ChatGPT-o4-mini required approximately 9 minutes of processing time to complete the

Mitigation analysis step of the CISA Interlock advisory, successfully analyzing a total of 52 mitigations. Each mitigation contained an average of 4 steps, with each step containing an average of 2 commands. The quality of its first response was deemed satisfactory and only one edit was required on the part of the analyst.
On two separate attempts, ChatGPT-o4-mini was unable to complete the Detections analysis step of the CISA Interlock advisory in under 30 minutes. On the first attempt, it appeared as though the model’s API calls were timing out or receiving no response from OpenAI. On the second attempt, multiple validation errors occurred which were similar to those pictured the ChatGPT-5-nano results. Finally on the third attempt, which took an approximate 2 minutes

and 40 seconds, ChatGPT-o4-mini returned a response containing 99 detections. Each detection contained an average of 3 steps, with each detection step containing an average of 3 commands. This response was evaluated as satisfactory and no edits were required on the part of the analyst.
ChatGPT-o4-mini - Worst-Case Scenario
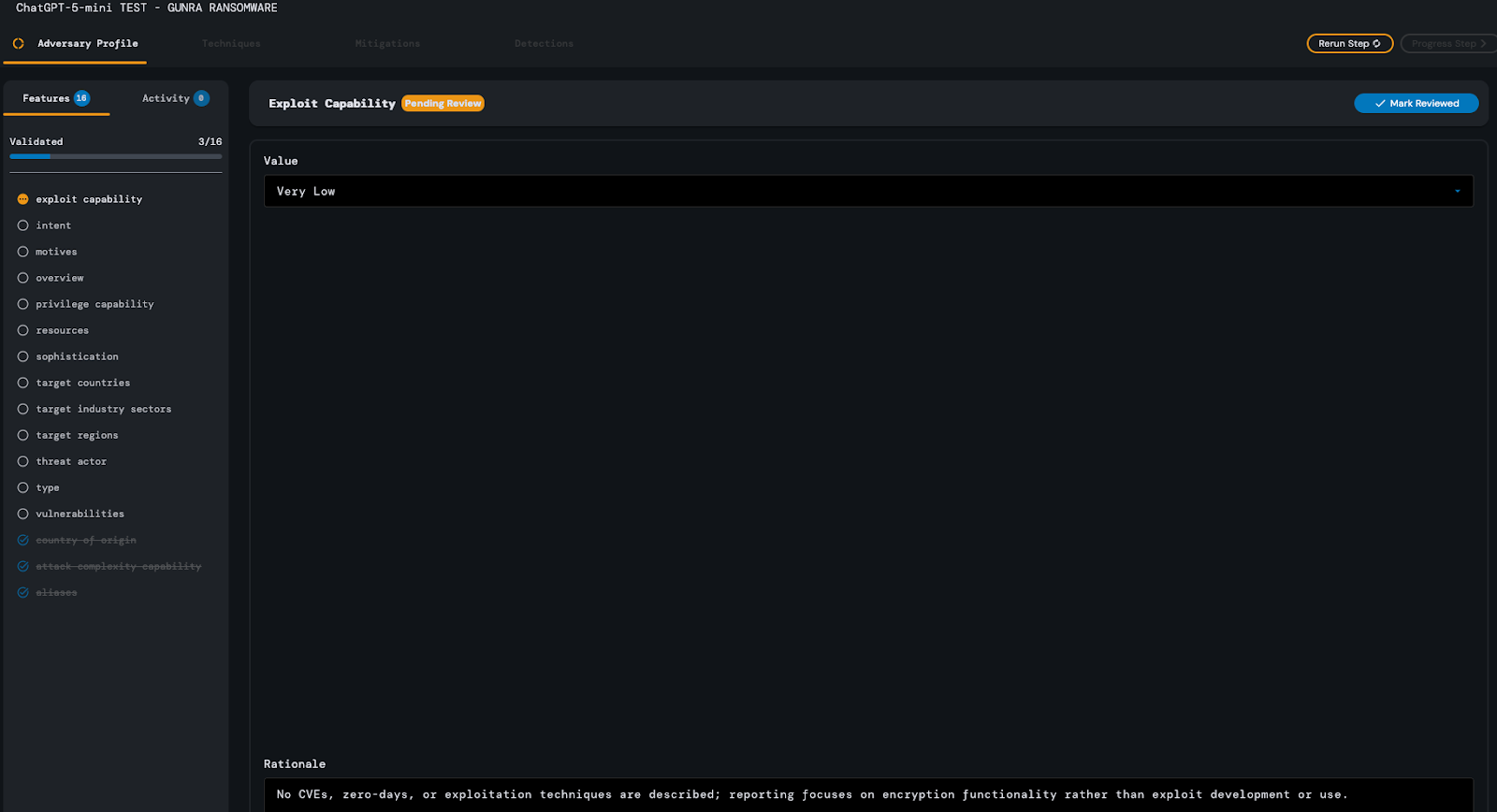
ChatGPT-o4-mini’s Adversary Profile analysis step of the Gunra Ransomware article required approximately 27 seconds of processing time. During its analysis, similar to the other models,

ChatGPT-o4 mistakenly attributed the adversary’s exploit capability as “Very Low,” citing a lack of explicit mention of the successful use of CVEs by the adversary.
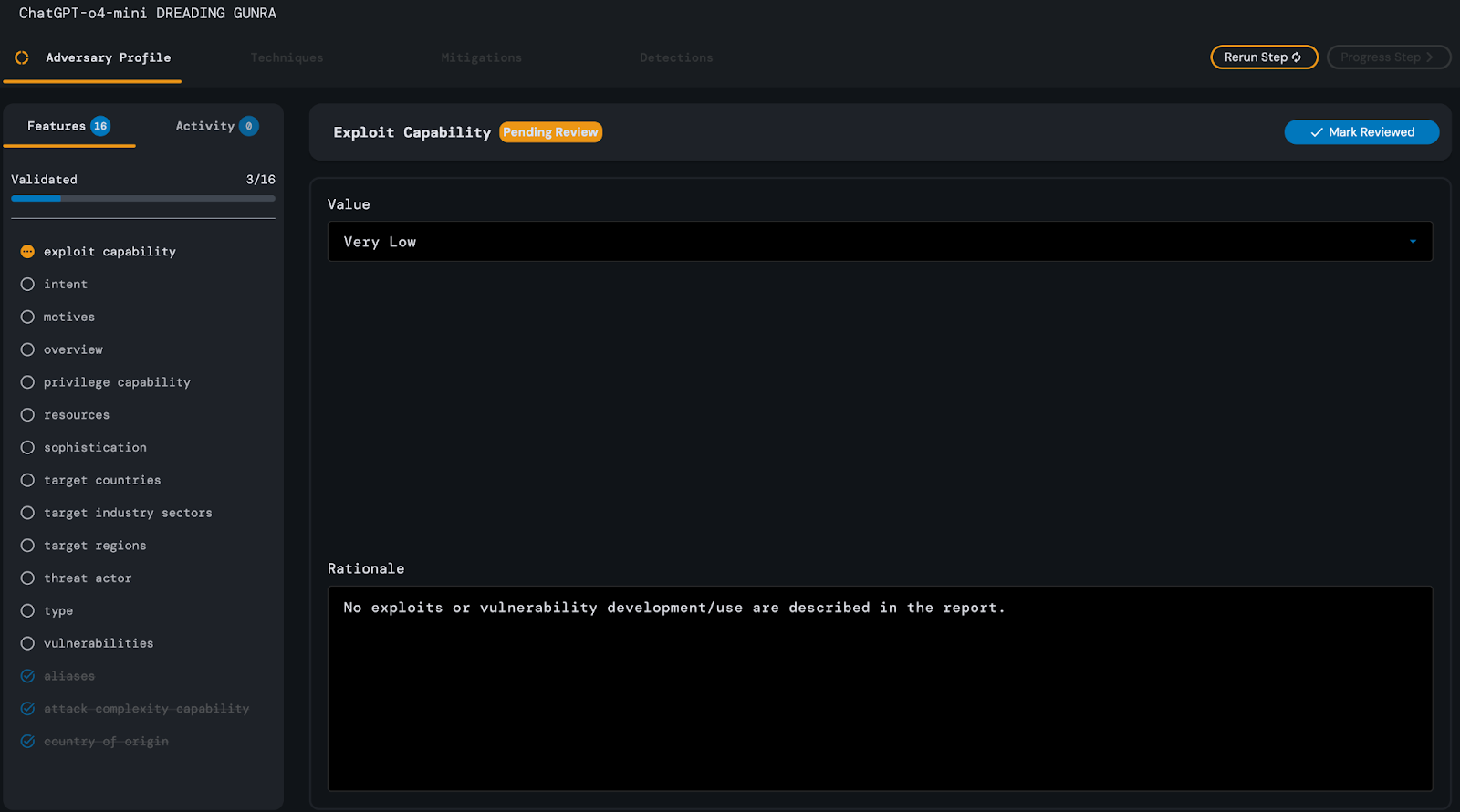
The model also failed to identify disruption of service or information theft as intents of the adversary, appearing to focus on their financial motivation.
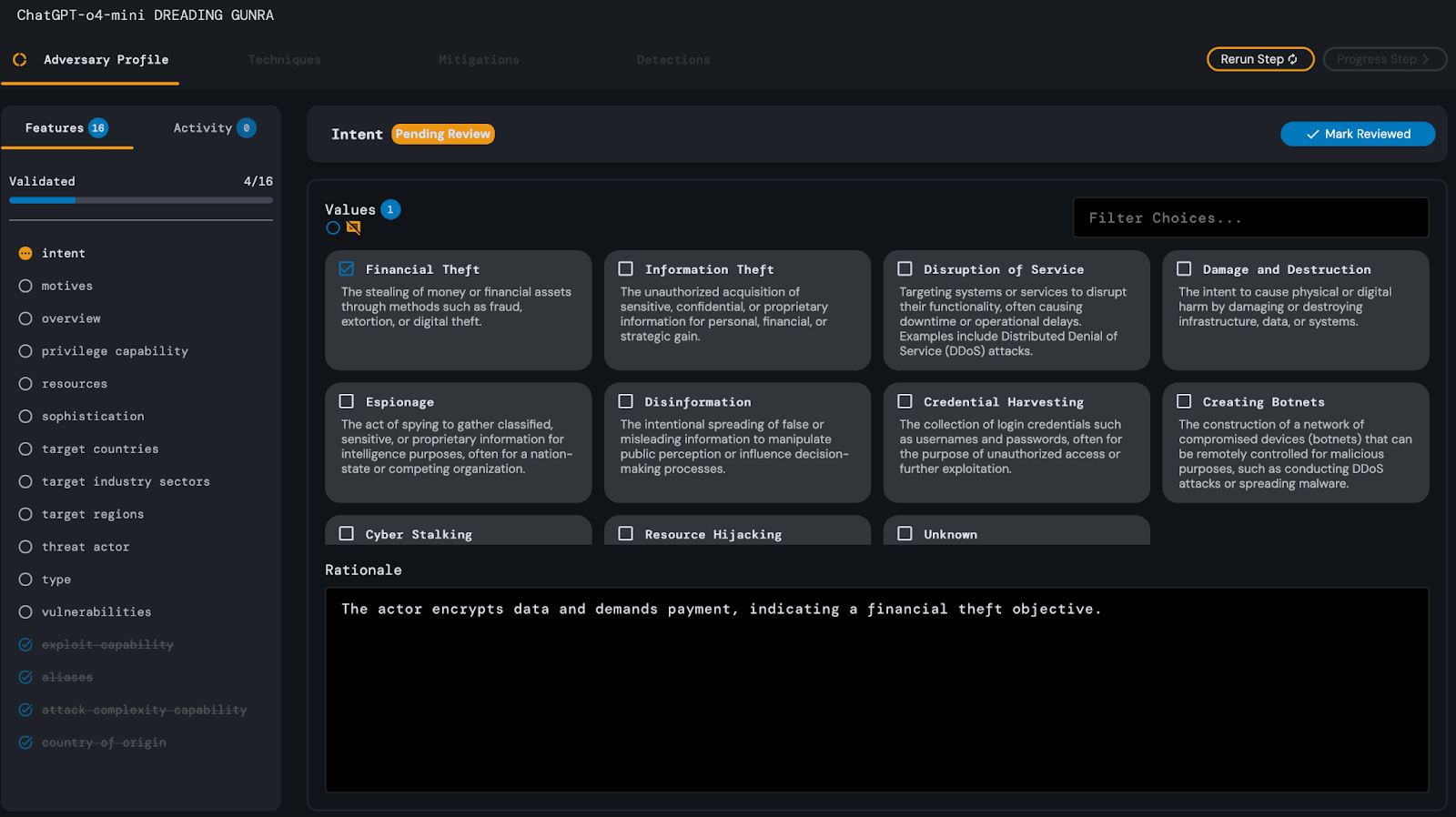
Asides from these two errors, the model’s response was evaluated and deemed satisfactory, requiring no additional editing on the part of the analyst.
After approximately 1 minute and 3 seconds, ChatGPT-o4-mini successfully

analyzed the Techniques step of the Gunra Ransomware article. It inferred two MITRE ATT&CK techniques, T1486 and T1567. Its analysis required minimal edits on the part of the
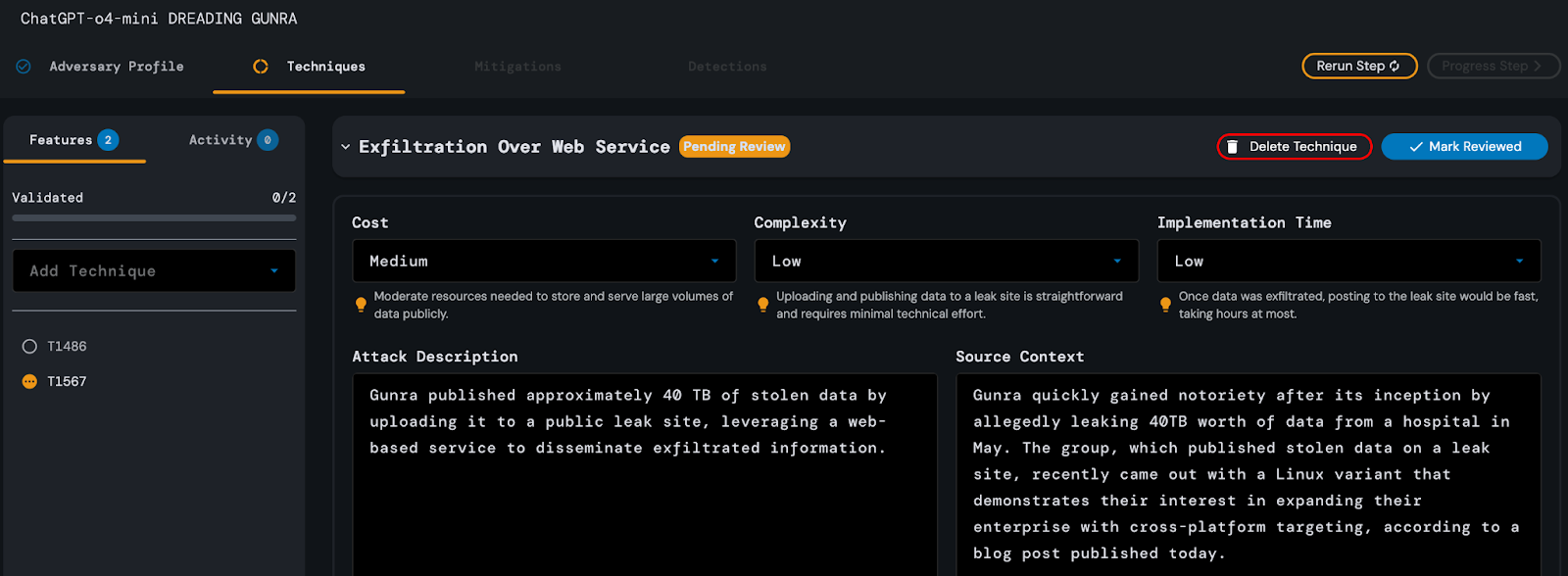
analyst, but was deemed satisfactory nonetheless. Subsequent reruns of the technique step took similar amounts of time and did not produce results with noticeable improvements over the original.
ChatGPT-o4-mini required approximately 3 minutes and 13 seconds to complete the Mitigations step analysis of the Gunra Ransomware threat report. Its analysis returned a

satisfactory response which contained three mitigations, each containing an average of 5 steps, with each step containing an average of 2 commands. Only one edit was required on the part of the analyst for this step.
After approximately 3 minutes and 22 seconds, ChatGPT-o4-mini successfully analyzed the Detections step of the Gunra Ransomware threat report. Its response contained 14 detections,

with each detection containing an average of 3 steps, and each step containing an average of 2 commands. This response was evaluated as satisfactory and no additional edits were required on the part of the analyst.

Latest Articles




Rising Threats from Iranian Cyber Actors: Why OT Operators Can’t Afford to Stay Reactive








